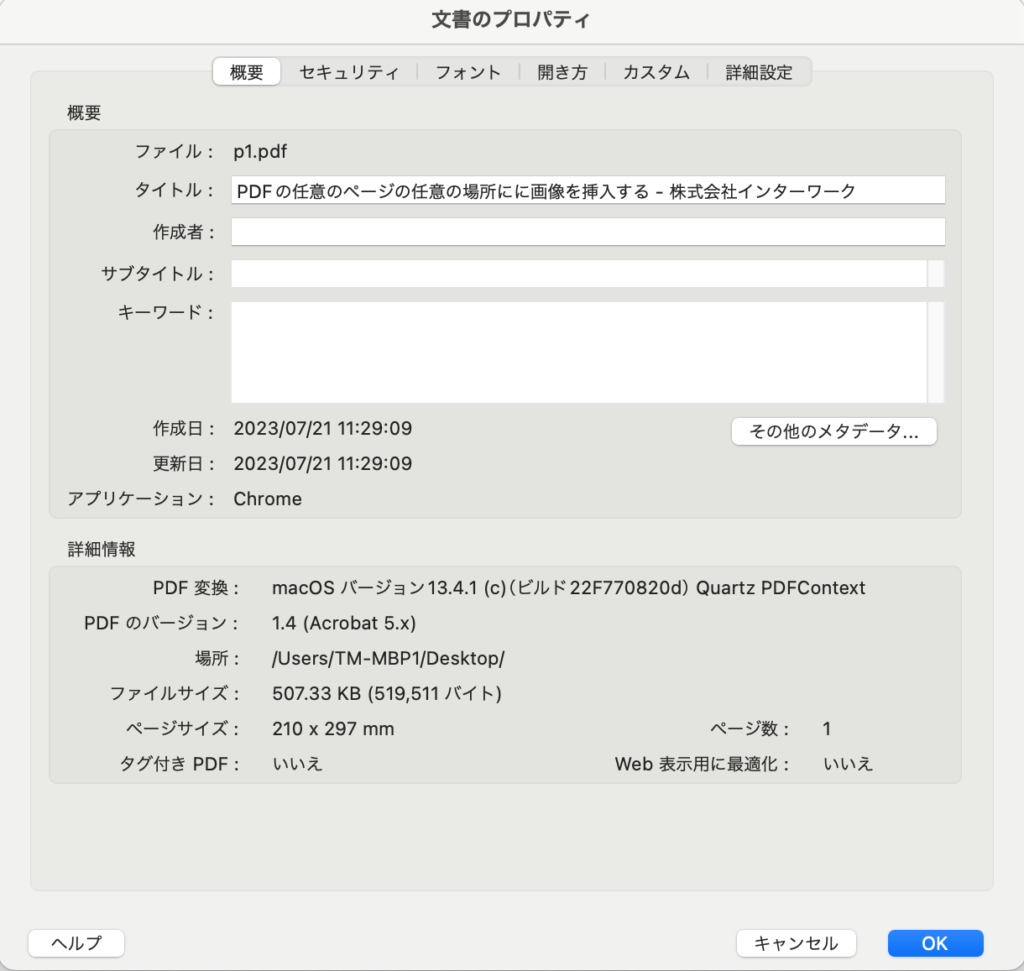
PDFファイルが構造化されているかどうかを確認するには、非常に簡単な方法があります。Adobe Acrobat Readerでファイルを開き、プロパティメニューを見てください。タグ付きPDFメニューオプション(詳細セクションの左下の項目)が、PDFにタグが含まれているかどうかを教えてくれます。この場合は含まれていません。
また、JPedalにはPDFUtilitiesクラスがあり、ファイルがPDF仕様に従って完全にタグ付けされているかどうかをプログラムでチェックすることができます。



PDFファイルが構造化されているかどうかを確認するには、非常に簡単な方法があります。Adobe Acrobat Readerでファイルを開き、プロパティメニューを見てください。タグ付きPDFメニューオプション(詳細セクションの左下の項目)が、PDFにタグが含まれているかどうかを教えてくれます。この場合は含まれていません。
また、JPedalにはPDFUtilitiesクラスがあり、ファイルがPDF仕様に従って完全にタグ付けされているかどうかをプログラムでチェックすることができます。

