

JPedalなら例えばこんな風に
PDFファイルは非常に複雑なバイナリとテキストのハイブリッドデータ構造です。PDFファイルのテキストを作成するためには、多くのソースからデータを解析し、組み立てる必要があります。 この例では、JPedal Java PDFライブラリを使用したサンプルコードとともに解説しています。
1.JPedalライブラリをダウンロードし、Javaプロジェクトに追加する。
2.JavaでJPedalライブラリの “ExtractTextInRectangle “クラスを使ってPDFファイルからテキストを抽出する。
ExtractTextInRectangle extract=new ExtractTextInRectangle("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
int pageCount=extract.getPageCount();
for (int page=1; page<=pageCount; page++) {
String text=extract.getTextOnPage(page);
}
}
extract.closePDFfile();
3.PDFが構造化されている場合、同じ “ExtractTextInRectangle “クラスを使用してタグ付けされたテキストを抽出します。この API は、テキスト内容を Java 文書 (Javadoc) 内の構造化された内容としてページから抽出することを可能にします。
ExtractTextInRectangle extract=new ExtractTextInRectangle("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
int pageCount=extract.getPageCount();
for (int page=1; page<=pageCount; page++) {
String text=extract.getTextOnPage(page);
}
}
extract.closePDFfile();
4.”ExtractTextAsWordlist “を使用して、JPedalライブラリを使用してJavaでPDFから単語を抽出します。このAPIを使えば、PDFファイルからすべての単語を、画面上のテキスト位置とともに簡単に抽出することができます(Javadoc)。
ExtractTextAsWordlist extract=new ExtractTextAsWordlist("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
int pageCount=extract.getPageCount();
for (int page=1; page<=pageCount; page++) {
List wordList=extract.getWordsOnPage(page);
}
}
extract.closePDFfile();
5.JPedalライブラリが提供する “ExtractOutline “クラスを使ってPDFファイルから文書のアウトラインを抽出します。PDFファイルには、目次(Javadoc)を提供するための文書概要が含まれていることがよくあります。
ExtractOutline extract=new ExtractOutline("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
Document pdfOutline=extract.getPDFTextOutline();
}
extract.closePDFfile();
6.PDFを開くのにパスワードが必要な場合は、ファイルを開く前にsetPasswordメソッドを使用します。
7.PDFをURLからローカルシステムにダウンロードしてから、上記の抽出方法を適用します。
PDFファイルからテキストを読み取るには?
JPedalのような、PDFのコンテンツストリームを解釈しテキストを抽出する、テキスト抽出機能を備えたPDFライブラリを使う方法があります。PDFファイル内のテキストはどのように保存されていますか?
PDF内のテキストは、フォントの選択、グリフインデックスによる文字の定義、ページ上の位置の設定など、多くのコマンドを持つコンテンツストリームに格納されます。テキスト抽出は、プレーンテキストを読むのではなく、これらのコマンドを解釈する必要があるため、とても複雑です。コンテンツストリームを解析し、グリフを文字に正確にマッピングして抽出するには、専用のツールが必要です。PDFファイルのテキストは構造化されているでしょうか?
PDFがタグ付きPDFであれば、構造化されたテキストを含んでいる可能性があります。タグ付きPDFには、文書内容の論理構造と読み順に関する情報が含まれています。PDFファイルが構造化されているかどうかを確認するには、非常に簡単な方法があります。Adobe Acrobat Readerでファイルを開き、プロパティメニューを見てください。タグ付きPDFメニューオプション(詳細セクションの左下の項目)が、PDFにタグが含まれているかどうかを教えてくれます。この場合は含まれていません。
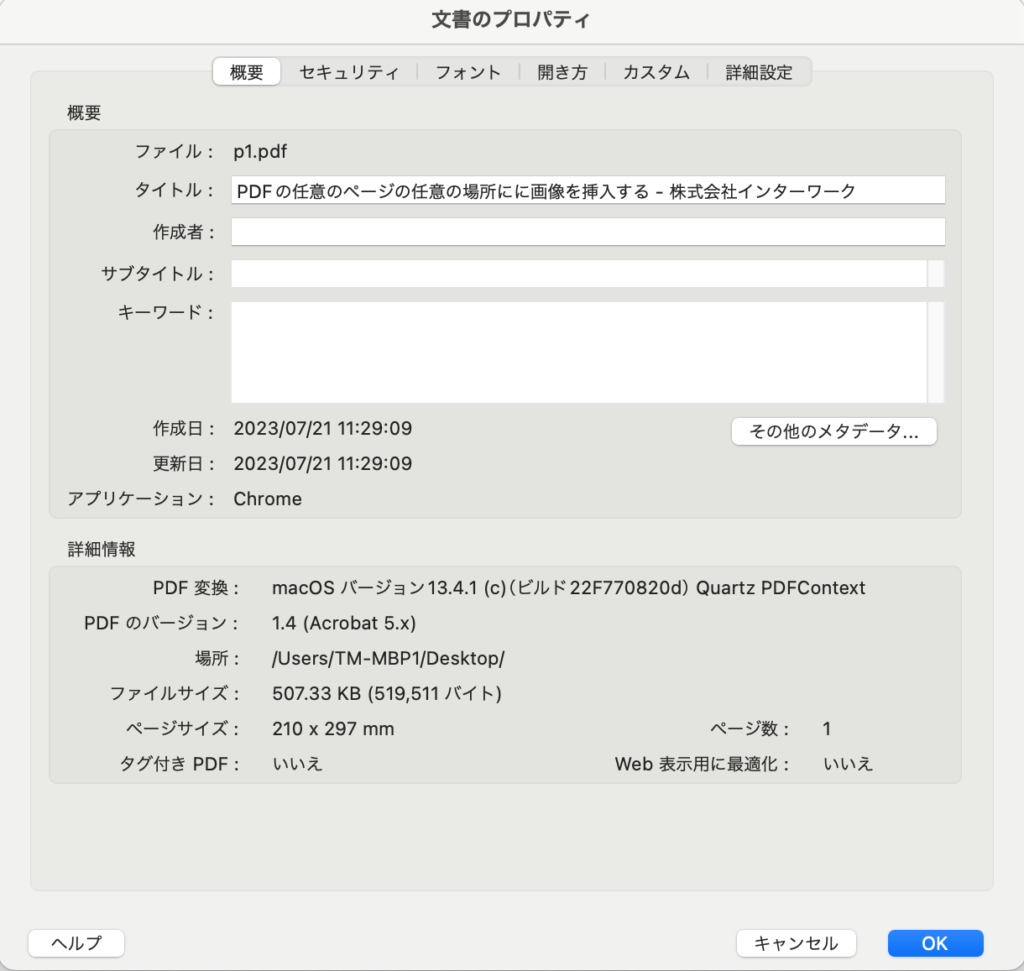
また、JPedalにはPDFUtilitiesクラスがあり、ファイルがPDF仕様に従って完全にタグ付けされているかどうかをプログラムでチェックすることができます。
PDFファイルからメタデータを読み取る方法は?
PDF内のメタデータ、例えば作成者、タイトル、作成日などは、文書のプロパティを解析できる専用のPDFツールを使って読み取ることができます。
例えば、以下はPDF 文書のプロパティの取得方法のサンプルコードです。
PDF 文書は、定義済みの文書プロパティのセット、または任意のデータを含む XML 値を含むことができます。
PdfUtilities extract=new PdfUtilities("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
Map mapOfValuePairs=extract.getDocumentPropertyStringValuesAsMap();
String XMLStringData=extract.getDocumentPropertyFieldsInXML();
}
extract.closePDFfile();
この他、ページ数の取得、PDFのページサイズと回転、しおり/アウトライン、フォントリスト、メタデータのXMLなどに利用できます。
PDFファイルから画像を読み取る方法は?
PDFの内部構造内の画像オブジェクトにナビゲートできるPDFライブラリの助けを借りて、PDFファイルから画像を抽出や切り抜きをすることができます。BMP、PNG、JPG、TIFFなど、さまざまな画像形式で画像を出力できます。
JPedalでPDFファイルから画像を抽出する方法:
1.PDFファイルを指すFile handle、InputStream、またはURLを作成します。ExtractImages extract = new ExtractImages(path);
2.ファイルがパスワードで保護されている場合は、パスワードを入力します。extract.setPassword("password");
3.PDFファイルを開きます。if (extract.openPDFFile()) {
4.各ページの画像を繰り返し処理します。
int pageCount = extract.getPageCount();
for (int page = 1; page <= pageCount; page++) {
int imagesOnPageCount = extract.getImageCount(page);
for (int image = 0; image < imagesOnPageCount; image++) {
BufferedImage img = extract.getImage(page,
image, true);
}
}
}
5.PDFファイルを閉じます。extract.closePDFfile();
PDFファイルを直接読むことはできますか?
PDFファイルはHTMLやTXTファイルのようなプレーンテキストではないため、PDFファイルを直接読むには、PDFリーダーまたはPDFフォーマットを解釈できるソフトウェアライブラリが必要です。
暗号化されたPDFファイルからテキストを読み取る方法は?
正しいパスワードとPDFリーダーが必要です。ロックを解除すると、必要に応じてテキストを表示、コピー、またはエクスポートすることができます。暗号化された文書にアクセスするための正しい権限と法的根拠があることを確認してください。
JavaでPDFを扱う開発には多機能・高性能な開発ライブラリー(SDK) JPedalがきっとお役に立つことと思います。JPedalは無料で試用していただけます。まずはご自身の環境で機能や品質をご確認のうえ、ぜひ導入をご検討ください。


